使用说明
数字人模型、传输模式、TTS、动作编排与并发用法。
3. Usage
分别选择数字人模型、传输方式、tts模型
3.1 数字人模型
支持4种模型:ernerf、musetalk、wav2lip、Ultralight-Digital-Human,默认用wav2lip
3.1.1 模型用wav2lip
- 下载模型
下载wav2lip运行需要的模型,链接:https://pan.quark.cn/s/83a750323ef0
将s3fd.pth拷到本项目wav2lip/face_detection/detection/sfd/s3fd.pth;
将wav2lip256.pth拷到本项目的models下, 重命名为wav2lip.pth;
将wav2lip256_avatar1.tar.gz解压后整个文件夹拷到本项目的data/avatars下 - 运行
python app.py –transport webrtc –model wav2lip –avatar_id wav2lip256_avatar1
用浏览器打开http://serverip:8010/webrtcapi.html
可以设置–batch_size 提高显卡利用率,设置–avatar_id 运行不同的数字人
替换成自己的数字人
python -m avatars.wav2lip.genavatar --video_path xxx.mp4 --img_size 256 --avatar_id wav2lip256_avatar1 #img_size固定为256,与模型相关
#生成文件在本项目data/avatars目录下
#如果一直卡住不动,可以将--face_det_batch_size改小一些
输入视频需要用闭嘴不说话的视频
3.1.2 模型用musetalk
- 安装依赖库
以下库只在生成avatar使用,推理不需要,如果有冲突可以单独建立一个环境安装
conda install ffmpeg
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"
- 下载模型
下载MuseTalk运行需要的模型,链接: https://pan.xunlei.com/s/VOW3nYho64jeCxT2sxrjcE7fA1?pwd=evnw
将models下文件拷到本项目的models下
musetalk_avatar1.tar.gz解压后将整个文件夹拷到本项目的data/avatars下 - 运行
python app.py --transport webrtc --model musetalk --avatar_id musetalk_avatar1
用浏览器打开http://serverip:8010/webrtcapi.html
可以设置–batch_size 提高显卡利用率,设置–avatar_id 运行不同的数字人
替换成自己的数字人
git clone https://github.com/TMElyralab/MuseTalk.git
cd MuseTalk
#修改configs/inference/realtime.yaml,将preparation改为True
python -m scripts.realtime_inference --inference_config configs/inference/realtime.yaml
#运行后将results/avatars下文件拷到本项目的data/avatars下
或者在livetalking项目中执行
python -m avatars.musetalk.genavatar --avatar_id musetalk_avatar1 --file ~/sun.mp4
#支持视频和图片生成,生成文件在本项目data/avatars目录下
输入视频需要用闭嘴不说话的视频
3.1.3 ER-Nerf
ernerf模型在git分支ernerf-rtmp,git checkout ernerf-rtmp
python app.py --transport webrtc --model ernerf
支持如下参数配置
3.1.3.1 音频特征用hubert
默认用的wav2vec,如果训练模型时用的hubert提取音频特征,用如下命令启动数字人
python app.py --transport webrtc --model ernerf --asr_model facebook/hubert-large-ls960-ft
3.1.3.2 设置头部背景图片
python app.py --transport webrtc --model ernerf --bg_img bc.jpg
3.1.3.3 全身视频贴回
- 1.切割训练用的视频
ffmpeg -i fullbody.mp4 -vf crop="400:400:100:5" train.mp4
用train.mp4训练模型
- 2.提取全身图片
ffmpeg -i fullbody.mp4 -vf fps=25 -qmin 1 -q:v 1 -start_number 0 data/fullbody/img/%08d.png
- 3.启动数字人
python app.py --transport webrtc --model ernerf --fullbody --fullbody_img data/fullbody/img --fullbody_offset_x 100 --fullbody_offset_y 5 --fullbody_width 580 --fullbody_height 1080 --W 400 --H 400
- –fullbody_width、–fullbody_height 全身视频的宽、高
- –W、–H 训练视频的宽、高
- ernerf训练第三步torso如果训练的不好,在拼接处会有接缝。可以在上面的命令加上–torso_imgs data/xxx/torso_imgs –preload 1,torso不用模型推理,直接用训练数据集里的torso图片。这种方式可能头颈处会有些人工痕迹。
替换成自己的数字人
替换成自己训练的模型https://github.com/Fictionarry/ER-NeRF,训练模型时音频特征要选wav2vec或者hubert
├── data
│ ├── data_kf.json (对应训练数据中的transforms_train.json)
│ ├── au.csv
│ ├── pretrained
│ └── └── ngp_kf.pth (对应训练后的模型ngp_ep00xx.pth)
3.1.4 模型用Ultralight-Digital-Human
- 制作avatar
先根据项目 https://github.com/anliyuan/Ultralight-Digital-Human 训练模型,
然后将Ultralight-Digital-Human项目下checkpoint_epoch_335.pth.tar和scrfd_2.5g_kps.onnx拷到本项目models下
运行
#checkpoint为训练后模型文件路径,目前只支持音频特征为hubert的模型;
#video_path提供一段训练人物闭嘴不说话的视频
python -m avatars.ultralight.genavatar --video_path xxx.mp4 --avatar_id ultralight_avatar1 --checkpoint xxx.pth
#生成文件在本项目data/avatars目录下
- 运行
python app.py –transport webrtc –model ultralight –avatar_id ultralight_avatar1
用浏览器打开http://serverip:8010/webrtcapi.html
可以设置–batch_size 提高显卡利用率,设置–avatar_id 运行不同的数字人
3.2 传输模式
支持webrtc、rtcpush、rtmp,默认用webrtc
3.2.1 webrtc p2p
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1
服务端需要开放端口 tcp:8010; udp:1-65536 用浏览器打开http://serverip:8010/webrtcapi.html
3.2.2 webrtc推送到srs
- 启动srs
export CANDIDATE='<服务器外网ip>'
docker run --rm --env CANDIDATE=$CANDIDATE \
-p 1935:1935 -p 8080:8080 -p 1985:1985 -p 8000:8000/udp \
registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5 \
objs/srs -c conf/rtc.conf
- 运行数字人
python app.py --transport rtcpush --push_url 'http://localhost:1985/rtc/v1/whip/?app=live&stream=livestream' --model wav2lip --avatar_id wav2lip256_avatar1
服务端需要开放端口 tcp:8000,8010,1985; udp:8000
用浏览器打开http://serverip:8010/rtcpushapi.html
如果推送地址不是localhost,需要在rtcpushapi.html中相应修改host地址
3.2.3 rtmp推送
安装rtmpstream库
https://github.com/lipku/python_rtmpstream启动rtmp服务器(此处用srs)
docker run --rm -it -p 1935:1935 -p 1985:1985 -p 8080:8080 registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5
- 运行数字人
python app.py --transport rtmp --push_url 'rtmp://localhost/live/livestream'
用浏览器打开http://serverip:8010/rtmpapi.html
如果推送地址不是localhost,需要在rtmpapi.html中相应修改host地址
rtmp也可以通过rtcpush到srs,由srs转成rtmp流
export CANDIDATE='<服务器外网ip>' #如果srs与浏览器访问在同一层级内网,不需要执行这步
docker run --rm --env CANDIDATE=$CANDIDATE \
-p 1935:1935 -p 8080:8080 -p 1985:1985 -p 8000:8000/udp \
registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5 \
objs/srs -c conf/rtc2rtmp
3.3 TTS模型
支持edgetts、gpt-sovits、fish-speech、xtts、cosyvoice。默认用edgetts,可通过REF_FILE指定音色
3.3.1 gpt-sovits
服务部署参照gpt-sovits
运行
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --tts gpt-sovits --TTS_SERVER http://127.0.0.1:9880 --REF_FILE ref.wav --REF_TEXT xxx
REF_TEXT为REF_FILE中语音内容,时长不宜过长。此处wav文件需要放在tts服务端,相对tts服务的路径。
3.3.2 fish-speech
服务部署参照fish-speech
运行
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --tts fishtts --TTS_SERVER http://127.0.0.1:8080 --REF_FILE test
–REF_FILE为fish-speech服务端的referenceid
3.3.3 cosyvoice
服务部署参照cosyvoice
运行
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --tts cosyvoice --TTS_SERVER http://127.0.0.1:50000 --REF_FILE ref.wav --REF_TEXT xxx
REF_TEXT为REF_FILE中语音内容,时长不宜过长。
3.3.4 腾讯语音服务
运行
export TENCENT_APPID=xxx #appid
export TENCENT_SECRET_KEY=xxx #seceret_key
export TENCENT_SECRET_ID=xxx #seceret_id
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --tts tencent --REF_FILE 101001
REF_FILE为音色ID,可以上https://cloud.tencent.com/document/product/1073/92668查看音色列表,也可以是自己克隆的音色id
3.3.5 豆包语音服务
运行
export DOUBAO_APPID=xxx #appid
export DOUBAO_TOKEN=xxx #accesss_token
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --tts doubao --REF_FILE zh_female_roumeinvyou_emo_v2_mars_bigtts
REF_FILE为音色ID,可以上https://www.volcengine.com/docs/6561/1257544查看音色列表,也可以是自己克隆的音色id
3.3.6 阿里千问语音服务
运行
export DASHSCOPE_API_KEY=<your_api_key>
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --tts qwen --REF_FILE Cherry
REF_FILE为音色ID,可以上https://help.aliyun.com/zh/model-studio/qwen-tts-realtime?spm=a2c4g.11186623.0.0.2f86cb646t1DwA#bac280ddf5a1u查看音色列表,也可以是自己克隆的音色id
3.3.7 xtts
运行xtts服务,参照https://github.com/coqui-ai/xtts-streaming-server
docker run --gpus=all -e COQUI_TOS_AGREED=1 --rm -p 9000:80 ghcr.io/coqui-ai/xtts-streaming-server:latest
然后运行,其中ref.wav为需要克隆的声音文件
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --tts xtts --REF_FILE data/ref.wav --TTS_SERVER http://localhost:9000
3.4 动作编排
- 1,生成素材
ffmpeg -i xxx.mp4 -vf fps=25 -qmin 1 -q:v 1 -start_number 0 data/customvideo/image/%08d.png
ffmpeg -i xxx.mp4 -vn -acodec pcm_s16le -ac 1 -ar 16000 data/customvideo/audio.wav
- 2,编辑data/custom_config.json
指定imgpath和audiopath。
设置audiotype,说明:0表示推理视频,不用设置;1表示静音视频,如果不设置默认用推理视频代替; 2以上自定义配置 - 3,运行
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --customvideo_config data/custom_config.json
- 4,打开http://
:8010/webrtcapi-custom.html
填写custom_config.json中配置的audiotype,点击切换视频。如果是audiotype为1的静音视频会自动切换,不需要手动点击。
3.5 使用LLM模型进行数字人对话
目前调用千问大模型api实现,与openai接口兼容。支持llm流式输出。如果需要与其他大模型对接,修改llm.py中api调用接口
export DASHSCOPE_API_KEY=<your_api_key>
根据传输模式用浏览器打开http://serverip:8010/rtcpushchat.html或http://serverip:8010/webrtcchat.html
3.6 多并发
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --max_session 3
通过max_session指定最多运行几个会话。然后打开多个webrtcapi.html
3.7 语音输入
- 用funasr语音识别
根据webrtc或rtcpush传输模式分别打开webrtcapi-asr.html或rtcpushapi-asr.html
先点击最上面的start按钮连接视频;然后点击下面语音采集框的连接、开始按钮;开始语音采集并驱动数字人播报(说完不需要点停止按钮,等数字人说完继续说下一句即可)
如果浏览器不能采集语音,在浏览器地址框输入edge://flags/#unsafely-treat-insecure-origin-as-secure,将服务端网址输入下面框中并重启浏览器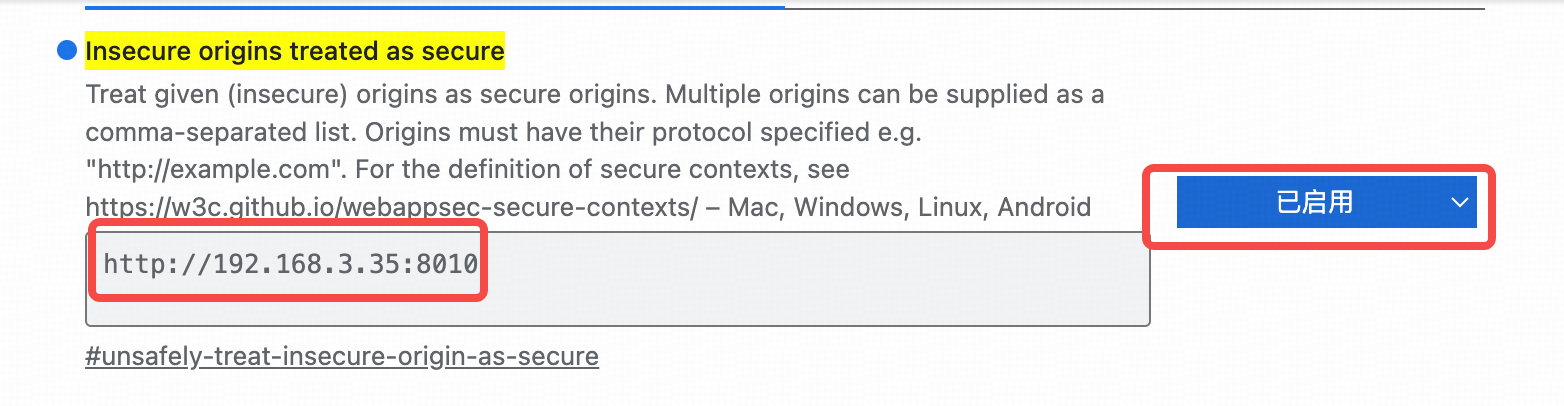 如果需要安装自己的asr服务端,请参照https://github.com/modelscope/FunASR/blob/main/runtime/python/websocket/README.md
如果需要安装自己的asr服务端,请参照https://github.com/modelscope/FunASR/blob/main/runtime/python/websocket/README.md - 用浏览器自带的语音识别
需要用到llm做对话,后台运行
export DASHSCOPE_API_KEY=<your_api_key>
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1
然后在浏览器中打开页面dashboard.html,由于需要采集音频,也需要像上一步一样在浏览器中加入白名单
3.8 虚拟摄像头输出
参考https://github.com/letmaik/pyvirtualcam安装虚拟摄像头驱动,然后运行
pip install pyvirtualcam
pip install pyaudio
python app.py --transport virtualcam --model wav2lip --avatar_id wav2lip256_avatar1
打开obs或者其他直播软件,摄像头输入选择虚拟摄像头,可以看到数字人视频
打开webrtcapi.html,不要点击start,直接输入文字,点击send,在obs能看到数字人说话